0. The Problem #
A couple of months ago, I had to implement scheduling logic for the data platform @ Embark Studios. Roughly, the problem boiled down to scheduling a DAG of hundreds of tasks as effectiently as possible.
A task can be distilled down to this:
from pydantic import BaseModel
class Task(BaseModel):
name: str
dependencies: List[Task] = []
async def doWork(self):
asyncio.sleep(1)That is, each task has a unique name and an optional list of dependencies. Each task is also doing
some async work. So a relatively simple list of tasks can look something like this:
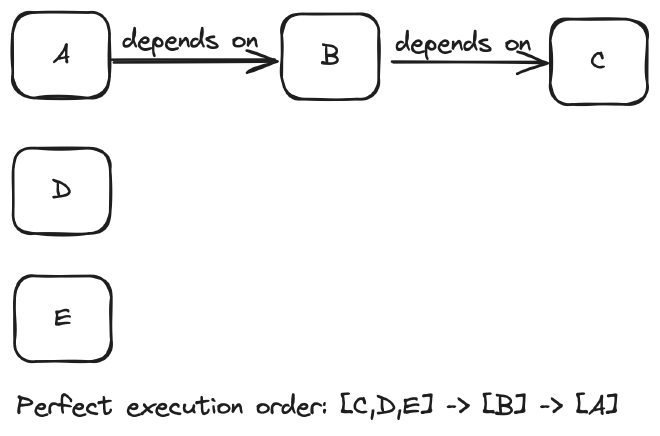
In the example above the ideal scheduling order would be to:
- Schedule tasks
C,DandEconcurrently - Once task
Ccompletes schedule taskB - Once task
Bcompletes schedule taskA
In reality, though, these DAGs accomadate hundreds of elements with intricate depenendencies between them.
1. Topological Sort #
Needless to say, this problem has been known in CS world for a while and what’s needed here is a topological sort, the nuance however was that in my case I also had to execute tasks in the correct order, not just sort them.
While thinking about a solution I stumbled upon a beatiful library, graphlib which did exactly what I needed and surprisingly enough is a part of Python standard library!
So let’s go through the process of scheduling DAG together!
1.1 Making definitions hashable #
To utilize the library we need to make changes to the task definition to make it hashable.
class Task(BaseModel):
name: str
dependencies: List[Task] = []
async def doWork(self):
asyncio.sleep(1)
+ def __hash__(self):
+ return hash(self.name)
+ def __eq__(self, other):
+ return self.name == other.name
1.2 Creating a scheduler #
Now we can create a simple scheduler that will accept a list of tasks and execute them in a proper order.
To do so we are creating a map, where each task is a key and the value is a list of dependencies, which can be achievied with a simple DFS pass through the list.
def schedule(tasks: List[Task]):
_schedule(_prepare_graph(tasks))
def _prepare_graph(tasks: list[Task]) -> dict[Task, set[Task]]:
graph = {}
for task in tasks:
_flatten(task, graph)
return graph
def _flatten(task: Task, graph: dict[Task, set[Task]]):
if task not in graph:
graph[task] = set()
for dep in task.dependencies:
graph[task].add(dep)
_flatten(dep, graph)1.3 Scheduling an update #
Now that we have a constructed graph, we can schedule the execution:
def _schedule(graph: dict[Task, list[Task]]):
sorter = TopologicalSorter(graph)
sorter.prepare()
while sorter.is_active():
for task in sorter.get_ready():
await task.doWork()
sorter.done(task)
Okay, so there are a bunch of things that are happening here, so lets go through them.
First of all, we are creating a TopologicalSorter object and call prepare on it. prepare
validates the graph and will raise an exception if a cycle is detected.
Then we iterate over the sorter until it is no longer active(i.e. until there are unprocessed
tasks available). We start a second loop by calling sorter.get_ready(), which returns a list of
tasks that are currently up for grabs, i.e. tasks, which do not depend on any other tasks OR tasks
which dependencies have been processed.
Finally, for each processed task we are calling sorter.done(task) which marks it completed and
allows sorter to progress further.
1.4 Handling failures #
This takes us quite far! However, there is a problem with the current implementation. Let’s say we have a DAG of tasks similar to the one we had earlier, but one of the tasks decides to blow up during the execution:

In the current implementation what will happen is that our scheduler will try to execute first
batch of tasks, C,D and E, but since E throws it will never progress any futher and, honestly,c
we will be lucky to process even the first batch completely!
To address this issue, we need to note a failure and continue our execution as far as possible. To do so we can create a Result structure:
class Result(BaseModel):
task: Task
success: bool
exception: Optional[Exception] = None
class Config:
# this for pydantic to allow arbitrary types, Exception in this case
arbitrary_types_allowed = True
Then in the scheduler we create a wrapper function for the tasks’ doWork method
async def _execute(task: Task) -> Result:
try:
await task.doWork()
return Result(task=task, success=True)
except Exception as e:
return Result(task=task, success=False, exception=e)
Now we need to tweak our _schedule function to work with results:
+async def _schedule(graph: dict[Task, set[Task]]) -> list[Result]:
sorter = TopologicalSorter(graph)
sorter.prepare()
+ results = []
while sorter.is_active():
+ tasks = []
for task in sorter.get_ready():
- await task.doWork()
- sorter.done(task)
+ tasks.append(_execute(task))
+ processed = await asyncio.gather(*tasks)
+ for p in processed:
+ sorter.done(p.task)
+ results.extend(processed)
+ return results
Now the entry point function can be changed to consider the execution results:
def schedule(tasks: List[Task]):
- _schedule(_prepare_graph(tasks))
+ results = _schedule(_prepare_graph(tasks))
+
+ failed_results = [result for result in results if not result.success]
+ succeeded_results = [result for result in results if result.success]
+ print(
+ f"Processed {len(succeeded_results)} tasks successfully and {len(failed_results)} +
+ tasks failed. Out of {len(tasks)} tasks."
+ )
2. Final result #
In the end client calls to the scheduler would look something like this:
if __name__ == "__main__":
task_c = Task(name="C",)
task_b = Task(name="B", dependencies=[task_c])
task_a = Task(name="A", dependencies=[task_b])
task_d = Task(name="D")
task_e = Task(name="E")
tasks = [task_a, task_b, task_c, task_d, task_e]
asyncio.run(schedule(tasks))
The source code is avaible here.
From my personal experience I can say that this deceivingly simple scheduler can be a quite formidable tool when it comes to async execution of tasks! :)